
Hace unos días comentamos cómo se encargaba git de guardar el contenido de los archivos, podéis encontrarlo aquí:
TL; DR Los datos son almacenados comprimidos en subcarpetas de .git/objects con un nombre resultado de calcular el hash SHA1 de su contenido.
En el pasado post se pudo apreciar que esos blobs se guardaban indistintamente del nombre del archivo, entonces eso deja una cuestión en el aire:
¿Cómo se gestionan las versiones de un archivo?
Para ellos git hace uso de otro de sus objetos, los de tipo tree. Se tratan de estructura de datos de tipo árbol ¡Ay! Aquellas maravillosas estructuras de datos. Estos tienen por nodos hojas objetos de tipo blob, es decir el contenido de los archivos. Pudiendo de esta manera almacenar una estructura de archivos que sustente distintas versiones entre sí. Os dejamos un pequeño diagrama que ayudará a entenderlo.

Figura 1: Ejemplo de estructura de datos de árbol
En la figura anterior podemos ver que tendríamos un árbol inicial que tiene como hijos un blob de datos llamado main.c y otro objeto de tipo tree en la ruta /src, a su vez este segundo tree está compuesto de dos objectos blob llamados lib.c y lib.h. Creo que con esto nos podemos hacer una idea de la potencia de este tipo de objetos.
Siguiendo con el repositorio que creamos en el post pasado, vamos a generar nuestro primer objecto de tipo tree con la primera versión del archivo test.txt:
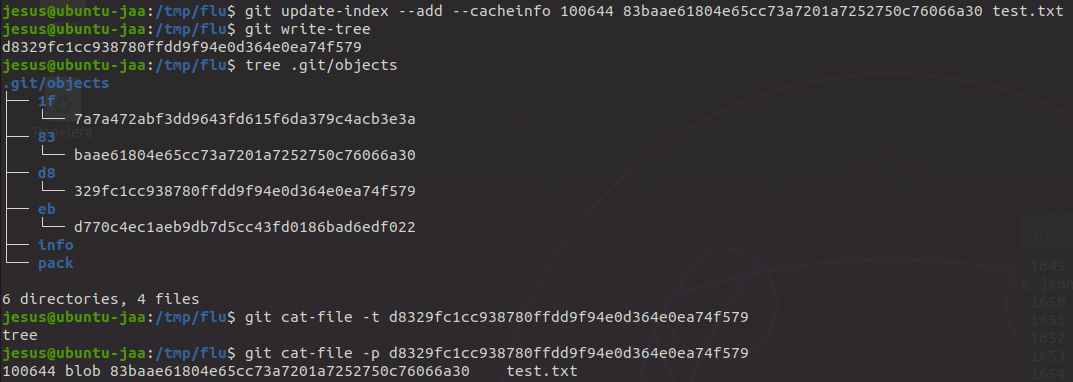
Creamos nuestro primer objeto de tipo tree
En este caso, por explicarlo un poco, con el comando git update-index nos encargamos de actualizar el indice actual, con --add y --cacheinfo indicamos que queremos añadir un archivo que no está preparado y que no existe en la carpeta, sino que está en la base de datos.
Los últimos parámetros hacen referencia a los permisos del archivo, en este caso 100644 indica que es un archivo (100) y que tendrá los permisos 644, también podríamos añadir un enlace simbólico con 120000, pero esto lo dejaremos para más adelante; y por último, el hash del objecto que guarda el contenido y el nombre que va a ocupar dentro de nuestro árbol.
Cabe destacar que si al comando git cat-file se le pasa la opción -t nos devuelve el tipo de objeto con el qué estamos tratando, en este caso un objeto de tipo tree. Vamos a crear ahora otro de estos objetos de tipo tree con la segunda versión del archivo test.txt:

Creamos nuestro segundo tree con un nuevo archivo llamado flu.txt
Se parte por defecto del índice anterior, sobre el que hemos actualizado el contenido de test.txt con su referencia a su segunda versión. Además hemos creado otro archivo (flu.txt) que al llamar a la función de actualizar el índice ha creado de manera automática el objecto 6c31009cc684a05dc92382c33581eb751e785463 con su contenido, esto lo ha hecho llamando al comando interno git hash-object que vimos en la anterior entrega, como se puede apreciar no es tan mágico después de todo. Por último, vamos a crear una estructura algo más compleja, como la que vimos en la primera imagen:

Un último tree que tiene un tree como carpeta
En este caso, mediante el uso de git read-tree indicamos que queremos que un tree forme parte del tree actual y mediante el uso del parámetro --prefix=carpeta se le indica dónde queremos colocarlo, o dicho de otro modo cual será la carpeta de este sistema de ficheros.

Figura 2: Representación gráfica de los dos primeros objetos tree creados

Figura 3: Representación gráfica del último objeto tree creado
Al final, hemos creado 3 objetos de tipo tree que siguen la estructura de las figuras anteriores de un modo sencillo. Cada uno de estos objetos de tipo tree se sigue almacenando en la carpeta .git/objects que en nuestro caso, ahora tiene esta forma:

Carpeta .git/objects del repositorio
Y en este segundo post ya nos podemos hacer una idea de cómo se referencian y estructuran los blobs de datos entre sí.
¿Se podrá hacer algo interesante con esto? Ya lo veremos en siguientes posts ;)
Agur yogur!